
大二上概率论考试前的一个小整理,之后不用捧着书了hhhh
概率论与数理统计
作为期中考试的复习资料
主要对一些基本概念进行整理,以及收录一些计算公式。
反正现在还算简单,之后还得微笑面对数值统计
(期中后的补充)
来了来了,数理统计(扶额痛哭
在期末版本中补充了一些结论的证明
价值不高,基本完全是抄书的,可以作为学习的参考,希望对各位能带来一定的帮助,恭祝各位在期末考中取得优异的成绩
概统够呛
概率论
基本概念
随机测试
我们将能在相同条件下重复进行的、每次测试结果不止一个,并事先明确所有可能结果的、在测试之前不能预测出现结果的试验称作随机测试
样本空间
随机测试E所有可能结果的集合称作E的样本空间,每种可能结果称作样本点
随机事件
E样本空间一部分样本点的集合称作E的随机事件
其中由单个样本点组成的事件称作基本事件,由全集组成的事件称作必然事件,空集组成的事件称作不可能事件
关系运算
包含、等价
,称作B事件包含A事件,指事件A的发生必然导致事件B的发生
在选择题时,可以通过作图画圆来辅助求解
如果同时有则称事件A和事件B相等 ,即
和关系
事件称为事件A和事件B的和事件,当且仅当AB之一发生时,有事件发生。
额外的,称事件为n个事件Ai的和事件,其中要求事件可列
积关系
事件称为事件A和事件B的积事件,当且仅当AB同时发生时,有事件发生。
额外的,称事件为n个事件Ai的积事件,其中要求事件可列
差关系
事件称为事件A和事件B的差事件,当且仅当A发生,B不发生,事件发生。
互斥关系
若则称事件A与B互斥,即两事件不可能同时发生
逆关系
若,称事件A与B为逆事件,即对于每次测试,必有AB之一发生
有
关系运算律
交换律、结合律、分配律
德摩根律:
频率(后验)
在相同条件下进行n次测试,在这n次测试中事件发生的次数称为事件发生的频数,频数和次数的比值被称作频率,记作fn(A)。频率表示一个事件在测试中发生的可能性
概率(先验)
设E是随机测试,S为其对应样本空间,对E中的每一事件A赋予特定的实数P(A),将之称作事件A的概率。如果集合函数P(·)满足非负性(P>=0)、规范性(对必然事件有P = 1)、可列可加性(),则可以用P表示事件在一次测试中发生可能性的大小
性质
(有限可加性)对于互不相融事件Ai,有
设事件A、B,若有,则有
等可能概型
超几何分布模型:
其中组合数C(r,a)的定义为
(要求a r为非负整数,且r≤a)
条件概率
称作在A事件发生的情况下事件B发生的条件概率。条件概率大于零,且对于必然事件B,有条件概率等于一。
条件概率同样有可列可加性:
推广上式可得相应的乘法公式
划分
设S为试验E的样本空间,Bi为E的一组事件,若
则称Bi为样本空间S的一个划分,对于划分有,单次测试有且仅有一个事件发生
全概率公式
全概率公式通过积累条件概率来近似推算P(A)
贝叶斯公式
可以简化作
证明:
独立性
满足的事件被称作独立事件
随机变量及其分布
随机变量
设定随机样本空间为S={e},X=X(e)是定义在样本空间上的实值单值函数(即仅与具体的元事件相关联),称X=X(e)为随机变量。随机变量是样本点事件到实数轴的一一映射。
离散型随机变量
离散型随机变量取值可列,且每个当值对应一个概率。描述离散型随机变量X的分布有
称之为离散型随机变量的分布率,对应的可以使用表格表示
| X | x1 | x2 | xn | ||
|---|---|---|---|---|---|
| pk | p1 | p2 | pn |
要求pi的累加和等于1或趋向于1(对于无穷可列离散型随机变量)
典型离散型随机变量
(0-1)分布
| X | 0 | 1 |
|---|---|---|
| pk | 1-p | p |
样本空间只有两种元素,仅进行一次测试的特殊分布
伯努利测试/二项分布
(0-1)分布进行多次重复试验的分布
进行n次测试,其中k次发生随机变量X对应事件的概率为:
二项分布记作
泊松分布
记作
对于二项分布,存在特性,其中npn=λ
当n较大时可以通过二项分布近似泊松分布,以简化计算
分布函数
对于随机变量X,和任意实数x,有X的分布函数
对于任意x1<x2,有
其中对离散型随机变量X有分布函数
另外的,对连续的随机变量,累加可以表示为积分
连续型随机变量
对于随机变量X的分布函数F(x),如存在非负可积函数f(x),使得对任意实数x有
则称X为连续型随机变量,f(x)为X的概率密度函数,与离散型随机变量的分布率对应
当x趋向于无穷时,F(x)取值为1
若f(x)在点x处连续,则有F'(x)=f(x),反之亦成立
特别的,有,即连续型随机变量在单值上概率密度为0
典型连续型随机变量
均匀分布
称X在区间(a,b)上均匀分布,记作
显然,其对应的分布函数从a到b由0均匀增加至1
指数分布
易得概率密度函数有对应的分布函数
指数分布存在一个特殊的性质,被称作无记忆性
正态分布
正态分布也被称为高斯分布,记作
关于正态分布的处理,通常会通过换元法统一转化为μ=0,σ=1的标准正态分布,其中概率密度和分布函数特别的表示为φ(x),Φ(x),有:
额外的,有
随机变量的函数分布
已知当前随机变量概率分布时,可以求得变量的函数的概率分布,如果函数g处处可导,且g‘大于0,即函数严格单调时,我们可以求得的分布
其中α=min{g(a),g(b)},β=max{g(a),g(b)},h(y)为g(x)的反函数
证明:
多维随机变量及其分布
二维随机变量
为了避免信息的过分丢失,我们将样本空间扩大到更高维的层面进行精确的描述。其中,将样本空间映射到一个二维平面上,即可获得二维的随机变量,即映射由两个坐标轴进行表示,写作(X,Y)。
我们同样用分布函数来对多维随机变量进行描述:
易知分布函数对于变量x和y都是不减函数,且当任一变量小于定义域时有F=0
对于离散型二维随机变量,我们能获得变量的联合分布率
这个联合分布率同样可以用表格表示,另外有联合分布函数
对于连续型随机变量,有
其中f(x,y)被称为随机变量的联合概率密度
随机变量落在映射平面上固定范围的概率为概率密度函数的积分
特别的,若f在点x,y处连续,有
边缘分布
虽然我们主要考虑的是二维随机变量(X,Y),但随机变量X和Y固然存在其自身的概率分布,记作FX(x)和FY(y),他们被称为二维随机变量的边缘分布函数,可以由F(x,y)确定,有:
类似的,我们可以得到Y的分布
条件分布
条件分布基于条件概率定义,讨论在随机事件发生的前提下另一随机变量的分布,易知,有:(为了节省打字量采用了极不严谨的写法)
对于指定的y,我们称该式为Y=y下X的条件概率分布
对于离散型随机变量可得X的分布率,有对应分布函数:
对于连续型,有X的密度函数,对应有条件分布函数:
相互独立
若两个事件相互独立,可以得出其对应的随机变量相互独立,即写作
对于n维随机变量,依旧如此推广
另外的,可以引申出一个结论,两个相互独立随机变量的函数也相互独立
函数分布
Z=X+Y
Z=XY
Z = max/min{X,Y}
随机变量的数字特征
数学期望
数学期望简称期望,又称作均值,记作E(x),是一个用以表征分布重心的实数
数学表示为单值的获取概率与其值的积在整个分布上的和
对于离散型随机变量,有
对于连续型随机变量,有
数学期望E(x)完全由随机变量X的概率分布决定,若X服从特定分布,则称E(x)为该分布的数学期望
特殊分布的数学期望
函数的数学期望
设Y是随机变量X的函数:Y=g(X)
对于离散型随机变量
对于连续型随机变量
对于两者,均要求有期望值绝对收敛
该定理同样可以推广到多个随机变量函数的情况,有
该公式同样适用于二维随机变量仅考虑单变量期望的情况
数学期望的性质
- 设C是常数,有E(C)=C
- 设X为随机变量,C是常数,有E(CX)=CE(X)
- 设X,Y是两个随机变量,则有E(X+Y)=E(X)+E(Y)
- 设X,Y是相互独立随机变量,有E(XY)=E(X)E(Y)
方差
方差是用来表征随机变量与其均值偏离程度的数字特征
设X为一个随机变量,有
记D/Var为随机变量X的方差
另引入量记作,称为标准差/均方差
对于离散型随机变量,有
对于连续型随机变量,有
通常的,给出计算公式
特殊分布的方差
方差的性质
设C是常数,D(C)=0
设X是随机变量,C是常数,D(CX)=C2D(X),D(X+C)=D(X)
设X,Y是两个随机变量,则有
D(X+Y)=D(X)+D(Y)+2E{(X-E(X))(Y-E(Y))}
当XY相互独立时,有去除余项
D(X)=0的充要条件是P{X=E(X)}=1
切比雪夫不等式
设随机变量X具有数学期望E(X)=μ,方差D(X)=σ2,则对任意正数ε,有
通常的,切比雪夫不等式被用作概率估算的方法
协方差与相关系数
对于多维随机变量,除了要讨论期望和方差,有时还需要讨论随机变量间的关系特征
仅对二维随机变量,经前面的探讨,有如果随机变量相互独立E{[X-E(X)] [Y-E(Y)]}=0
因此的,我们可以发现该式具有表现两随机变量关联性的特征,于是定义协方差
由定义可知:
给出协方差的部分性质:
相关系数
给定定理
|ρXY|≤1
|ρXY|=1的充要条件是,存在常数a,b使
有相干系数表示两个随机变量间的联系,对于相干系数趋向于1时,有随机变量间线性关系紧密,而相关系数较小时,有关联程度弱。
其中特例为相关系数=0时,称随机变量不相关。
矩与协方差矩阵
矩
原点矩
称为X的k阶原点矩
原点矩表示元素成分距离原点的分布情况,其中k阶为维度约束,表示在不同维度(层次)上变量距离中心的距离,可以结合范数进行理解。给出图片,这里的表示的是三变量混合分布下的不同范数约束
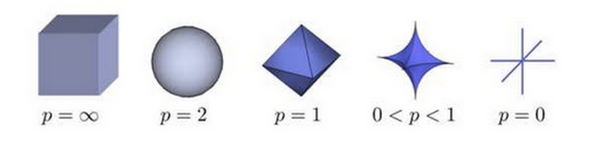
中心矩
称为X的k阶中心矩
中心距和原点矩的概念其实类似,只是把原点位移到了变量期望的位置
混合矩
称为X和Y的k+l阶混合矩
混合中心矩
称为X和Y的k+l阶混合中心矩
拾遗
显然的,我们可以看出数学期望即为一阶原点矩,而方差即为二阶中心矩,协方差则为二阶混合中心矩
协方差矩阵
协方差矩阵是为了讨论随机变量间的关联性及其方差引入的分布矩阵特性矩阵
假设有n维随机变量Xi的二阶混合中心矩均存在,即
均存在,我们将其排列为矩阵形式,称矩阵
为协方差矩阵,有协方差矩阵为对称矩阵(储存结构了解一下(唐突数据结构草
统计基本定理
大数定律
辛钦大数定理
设随机变量序列Xk相互独立,服从同分布,且具有数学期望E(Xk)=μ。则作前n个变量的算术平均值,对于任意ε>0,有
由切比雪夫不等式推导,令n趋向于0,由夹逼P=1
同时称Xn依概率收敛于μ,现给出弱大数定理的另一种表示:
设随机变量Xk相互独立,服从同一分布且具有数学期望μ,则序列依概率收敛与μ,即
伯努利大数定理
设fA为n次独立重复试验中事件A发生的次数,p是事件A在每次试验中发生的概率
中心极限定理
感谢大畸佬同学的安利√
定理1:独立同分布的中心极限定理
设随机变量独立同分布,设其具有数学期望,方差
设随机变量之和的标准化变量
其分布函数Fn(x)对于任意x满足
定理2:李雅普诺夫定理(不考,暂略,待补充)
定理3:蒂莫夫-拉普拉斯定理
设随机变量ηn服从参数为n,p的二项分布,则对任意x,有
数理统计
通过试验和观察获得的数据进行抽样,对概率分布进行分析
样本与抽样分布
随机样本
研究有关对象的某一数量指标视为统计对象,为考虑与该指标分布相关的随机变量,需要对该指标进行定量的观察,将试验的全体可观察值称作总体,将单个特定观察值视为个体,总体包含个体个数称作样本容量,通过个体数量划分有限总体和无限总体
在实际中,总体的分布通常是未知的,为此,我们需要从总体中进行抽样,取一系列独立同分布的个体作为样本,而对于其中抽取的样本数,被称作样本容量。其中每次的个体观察值被称作样本值
对于样本,有分布函数和概率密度
抽样分布
样本同样存在均值、方差、均方差、原点矩、中心矩
*关于样本方差中的n-1
这里给出的是推论公式,不管怎么说看到这里应该也不至于对这个结论过度纠结了
不过为了增进理解,这里结合知乎选手张英峰给出的理解作两句总结,有兴趣的同学可以去看看原链接
为什么样本方差(sample variance)的分母是 n-1?
即在我们在样本方差的计算中引入了一个作为限制因素,缩小了分布的自由度,因此估计量无法继续表示的无偏估计,遂经过严密的证明对样本方差进行了修正。
分布
设Xk是来自总体N(0,1)的样本,称统计量
服从自由度为n的分布,记作
分布的性质
分布有概率密度函数
首先给出一下函数的介绍吧,这里附上参考链接
函数实际上是泊松分布的一种变体,一种较高纬度的连续化表示,有
可加性
数学期望\方差
分位点
定义分位点
对于给定整数,满足
则称点称为分布上的α分位点,对于充分大的n,卡方分布的α分位点存在
其中为标准正态分布上的α分位点,有
通过关系可推,
分布的现实意义
首先给出我认为的卡方分布的基本意义,即检验样本相较于期望的离散化程度
卡方分布的表达式是一系列服从标准正态分布随机变量的平方和,其中随机变量的个数被称作卡方分布的自由度,这里给出不同自由度下卡方分布的概率密度图像
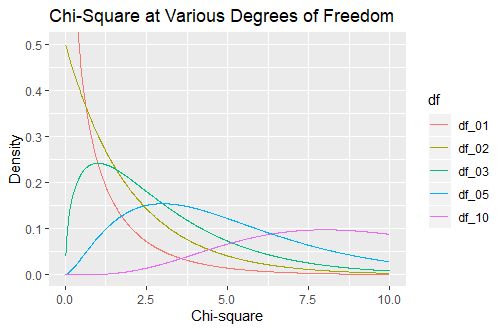
自由度n表示存在独立变量的个数,亦表示单个变量对整体分布影响的大小,自由度越大,有分布图象越趋向于对称。
卡方分布的特性基于X的分布,自由度n的卡方分布表示的是累计抽样带来的,n次试验结果与期望的累计偏差。
在图像上来看,卡方分布与泊松分布存在一定的相似性(由于函数的性质)
分布
设,且X,Y相互独立,则称随机变量
服从自由度为n的t分布,记作
分布的性质
分布存在概率密度函数
当t分布中的自由度n充分大时,有概率密度函数趋近于标准正态分布
有t分布的上分位点
当n>45时,可以由标准正态分布近似
另由对称性可得
分布的现实意义
t分布被广泛的用于小样本假设验证,用于排除异常数据的干扰,准确把握数据的集中趋势和离散趋势,即消除异常数据的干扰判断,判定模型均值与实际分布的关联性

在大样本情况下,易得有t检验与z检验等价
由于t分布的数学表示是一个标准正态分布除以一个卡方分布,前面有提到的,卡方分布表示的是随机变量相较期望偏移度的积累,因而其倒数也可以表示为对偏移的容忍度。
观察自由度趋近于无穷的t分布曲线,即标准正态分布曲线,我们可以发现,在我们要考虑问题的实际范围内,t分布相较正态分布曲线收敛度相对较低,因而有可以更好容纳偏移期望数据的特性,具有更强的鲁棒性和收敛力
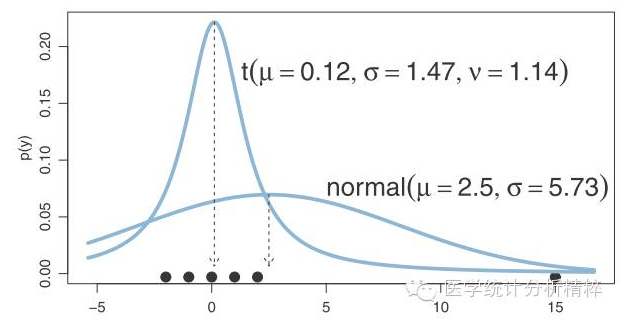
这里给出的是面对同样样本的t分布和高斯分布检验结果,显然的,t分布可以较好地排除异常样本的干扰
分布
设相互独立,称随机变量
服从自由度为(n1,n2)的F分布,记作
分布的性质
有分布的概率密度
由定义知
有F分布的上分位点
另有性质
分布的现实意义
F分布通常用于检验两种分布的方差之间的关系,即表现为两卡方分布对样本与期望的偏离度正则化后之比
正态总体下的分布关系
对于单分布下样本
- 和相互独立
对于两独立分布下样本
当时
对于方差相等的分布,定义U,V
参数估计
点估计
点估计是在处理一个估计问题,即有总体X的分布形式已知,但有一个或多个参数未知,我们可以通过总体X的一个样本(包含一个或多个个体)来估计总体未知参数的值。
点估计问题的一般提法为:设总体X的分布函数F(x;θ)的形式已知,θ为待估参数,Xk为X的一个样本,xk为相应样本值,点估计问题在于构造一个适当统计量,用其观察值作为未知参数的近似值。有称为θ的估计量,观察值确定的估计量为估计值,统称估计
矩估计
设X为随机变量,服从分布,其中为待估参数,有为来自X的样本,我们假定总体X的前k阶矩
由于已知样本矩依概率收敛于相应总体矩μl,我们使用样本矩作为相应总体矩的估计量,表现为联立解方程
我们称其为矩估计量,对应观察值为矩估计值
最大似然估计
先将条件限制在单参数求解上,构建似然函数
即一个通过现有概率分布,既定样本值,对待定参数θ进行估计的函数。我们使用最大估计法,在θ的取值范围Θ内通过最大化似然函数来获取最大的参数值θ作为估计量,有
称估计为最大似然估计。
对最大似然估计的求解方法有令方程
即取对数似然方程为0时,L导数为0,L取极大值
区间估计
区间估计可以理解为加上了置信区间的点估计,给出一个区间包含了参数θ的可能性即置信水平
置信区间
对于分布函数,的未知参数,给定真值α,确定两个统计量,要求其满足
则称随机区间是θ置信水平为1-α的置信区间,而barθ和underlineθ分别为置信水平为1-α的双侧置信区间的置信下限和置信上限
对于标准正态分布,通常有通过上下α分位点来确定置信区间,即对于
有置信区间为
正态总体均值与方差的区间估计
对于单个总体
给定置信水平1-α,为样本的均值和方差,考虑均值μ和方差σ2的置信区间
均值μ
对于已知σ2,有枢轴量的置信区间
对于未知σ2,我们以S为σ的无偏估计进行替代,有
取作为枢轴量,通过t分布的α分位点构建μ的置信区间
方差σ2
有μ未知,由σ的无偏估计S构建
取构建枢轴量,通过卡方分布的α分位点构建方差的置信区间
对于多个总体
给定置信水平1-α,给出两不同总体中样本的均值和方差,考虑均值间和方差间的关系
均值差
对于已知σ,有样本均值为总体均值的无偏估计,有
即
取左侧函数为枢轴量,根据标准正态分布的α分位点构建置信区间
对于未知σ,用无偏估计S代替
取枢轴量,继续有依据t分布α分位点构建置信区间
有
方差比
对于总体均值未知,根据样本方差估计总体方差,即使用F分布
取枢轴量,根据F分布的α分位点构建置信区间
特别的,对于方差比关系,若置信区间包含1,有方差无显著性差异
| 待估参数 | 其它参数 | 枢轴量分布 | 置信区间 |
|---|---|---|---|
| 已知 | |||
| 未知 | |||
| 未知 | |||
| 已知 | |||
| 未知 | |||
| 未知 |
单侧置信区间
对于部分统计的构建,我们只关注统计量θ的下限或者上限,这将带来构建单侧置信区间的需求。对于给定值α和样本X,确定统计量,若对于任意θ∈Θ满足
则称随机区间是θ置信水平为1-α的单侧置信区间,统计量称为置信区间上限,类似的,可以构造单侧置信区间下限
考虑正态总体X,若均值μ,方差σ2均未知,构建
有单侧置信区间
假设检验
假设检验是对估计和分布的综合运用,用于检验推断是否能符合现实情况,以及用于判定我们是否愿意接受一个结论。对于解决这个问题,我们给出一组定义
原假设
表示为,表示假设样本的期望μ符合μ0,
备择假设
表示为,表示假设样本的期望μ不符合μ0
显著性水平
显著性水平α,用于判定假设与事实是否存在显著性差异的标准,与α分位点的概念联系
检验统计量
构建类似于枢轴量的检验统计量,通过对构建统计量进行检验来判定假设是否符合事实
拒绝域
当检验统计量取到某区域中的值时,选择拒绝原假设,将这样的区域定义为拒绝域,拒绝域的选择与显著性水平具有特定联系
拒绝域的构建在于防止错误决策发生,我们通常对两种主要的错误进行考虑,并通过显著性水平对犯错误的概率进行约束
在实际问题中,两类错误的概率总是此消彼长,在实际运用中,我们主要考虑第一类错误的概率,并为α取一个不至于太小的值以确保第二类错误的概率不至于飙升
显著性检验
对第一类错误的概率加以控制的检验被称作显著性检验
显著性检验存在方向性,有双边检验与单边检验等操作,需要考虑实际问题进行检验
检验问题的求解
首先,考虑通过样本均值的观察值对μ进行估计,因为要求H0为真,所以需要保证观察均值与μ0的误差不至于太大,即,这里的k是与显著性相关的参数,当符合条件时,我们选择接受假设H
(对于方差检验具有另行的逻辑)
为了方便构造统计量,我们对公式进行一定的加工,得到检验统计量
通常,考虑边界值即拒绝域的临界点,检验问题被构造为这样的形式
构建检验量,通过α分位点的定义可以得出k对应Z检验量有
即,当检验量z绝对值的取值大于zα/2时,有H0被拒绝,而小于时,有接受
有拒绝域|z|≥zα/2
再以构造单边检验为例给出另一种构造形式
同样是得到该检验问题的拒绝域为
不难发现,构造拒绝域其实跟构造置信区间是互逆的,可以直接借用区间估计的公式
接下来给出不同假设问题的检验
检验实例
Z检验
σ已知,关于μ的检验
构造检验统计量
t检验
σ未知,关于μ的检验
构造检验统计量
Z检验(多总体)
σ已知,关于多个μ的检验
构造检验统计量
t检验(多总体)
σ未知(相等),关于多个μ的检验
有记
构造检验统计量
t检验(成对数据)
用于衡量差异,采用逐对比较法
有记表示基本无差异
构造检验统计量
卡方检验
μ未知,关于σ的检验
有记表示方差符合σ0
构造检验统计量
F检验
μ未知,关于多个σ的检验
构造检验统计量
对于验证两主题的方差齐性,构造单边检验。有记,即限制σ之间的关系
为了确保样本方差的观察值之间的偏差不至于过大,给出拒绝域形式
通过第一类错误构建检验
即有
一张检验表格
| 条件 | 原假设H0 | 检验统计量 | 备择假设H1 | 拒绝域 |
|---|---|---|---|---|
| 已知 | ||||
| 未知 | ||||
| 已知 | ||||
| 已知 | ||||
| 未知 | ||||
| 已知 | ||||
| 成对数据 |
Comments NOTHING