
人工智能导论杀我
敢信?老师在跟我们讲了遗传之后,布置了遗传算法的大作业。
只讲遗传没讲算法,你们敢信??你们敢信??
硬着头皮冲。。。
题目
是的这是老师给我们的资料。。建议跳过
一、实验目的:
熟悉和掌握遗传算法的原理、流程和编码策略,并利用遗传求解函数优化问题,理解求解TSP问题的流程并测试主要参数对结果的影响。
二、实验原理:
旅行商问题,即TSP问题(Traveling Salesman Problem)是数学领域中著名问题之一。假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路经的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。TSP问题是一个组合优化问题。该问题可以被证明具有NPC计算复杂性。因此,任何能使该问题的求解得以简化的方法,都将受到高度的评价和关注。
遗传算法的基本思想正是基于模仿生物界遗传学的遗传过程。它把问题的参数用基因代表,把问题的解用染色体代表(在计算机里用二进制码表示),从而得到一个由具有不同染色体的个体组成的群体。这个群体在问题特定的环境里生存竞争,适者有最好的机会生存和产生后代。后代随机化地继承了父代的最好特征,并也在生存环境的控制支配下继续这一过程。群体的染色体都将逐渐适应环境,不断进化,最后收敛到一族最适应环境的类似个体,即得到问题最优的解。要求利用遗传算法求解TSP问题的最短路径。
三、实验内容:
1、参考实验系统给出的遗传算法核心代码,用遗传算法求解TSP的优化问题,分析遗传算法求解不同规模TSP问题的算法性能。
2、对于同一个TSP问题,分析种群规模、交叉概率和变异概率对算法结果的影响。
3、增加1种变异策略和1种个体选择概率分配策略,比较求解同一TSP问题时不同变异策略及不同个体选择分配策略对算法结果的影响。
4、上交源代码。
四、实验报告要求:
1、画出遗传算法求解TSP问题的流程图。
2、 分析遗传算法求解不同规模的TSP问题的算法性能。
3、对于同一个TSP问题,分析种群规模、交叉概率和变异概率对算法结果的影响。
4、增加1种变异策略和1种个体选择概率分配策略,比较求解同一TSP问题时不同变异策略及不同个体选择分配策略对算法结果的影响。
遗传算法简述
现学现卖的,请别计较太多(扶额
遗传算法(GA),即模拟生物遗传进化构建的智能算法,通过将解作为种群中的个体,解空间视为种群,通过繁殖/变异/优胜劣汰等自然选择手段,对解空间进行约束,从而培养最优个体的算法。
即,通过对个体优劣性的评定,通过个体的淘汰和繁殖变异更新种群(是否可以加入自然死亡呢?
算法的基本流程被概述为这样一张图
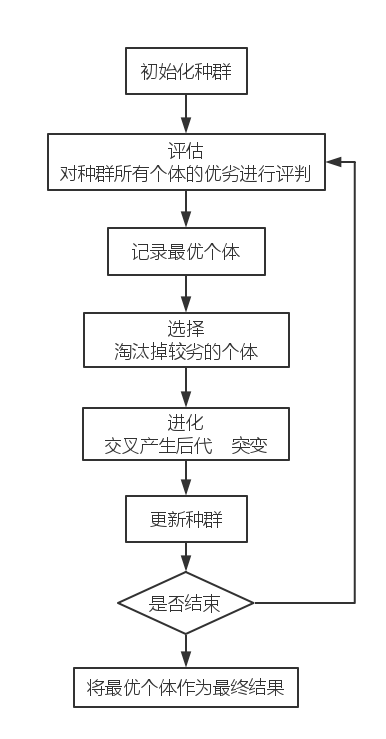
再这么的,我们试着为生物概念与遗传算法建立一个对应表(参考
| 生物遗传概念 | 遗传算法概念 |
|---|---|
| 个体 | 解 |
| 染色体 | 解的编码 |
| 基因 | 解编码中的结构化信息 |
| 碱基 | 解编码中可存在的元素 |
| 适应性 | 设计评价函数的值 |
| 种群 | 生成或给定的一组解 |
| 繁殖 | 通过解编码的重构生成新解 |
| 变异 | 解编码部分发生顺应变化规则的改变 |
| 适者生存 | 算法迭代过程中仅保留优质解 |
| 返祖 | 指求解过程中得到解的爸爸(?) |
让我们想想,如果遗传算法是原始社会的话,那么是否可以构建人类遗传算法
让我想想能plug点啥,作为DLC
| 人类社会概念 | HGA概念(? |
|---|---|
| 单身率 | 淘汰的缓和概念,单身过久导致死亡淘汰 |
| 多人运动 | 交叉兼容多个体(好像不太对劲 |
| 死亡年龄/死亡率 | 存活一定轮后随机死亡 |
| 结婚 | 繁殖前提,优秀基因马太效应,其他人没差 |
| 近似价值 | 个体优先与价值相似的个体喜结连理 |
| 相亲 | 从池子里随机抽取个体,差不多就在一起吧 |
| ······ | 回头再想,先干正事 |
问题建模
描述一下问题
TSP问题(Traveling Salesman Problem)。假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路经的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。TSP问题是一个组合优化问题。该问题可以被证明具有NPC计算复杂性。因此,任何能使该问题的求解得以简化的方法,都将受到高度的评价和关注。
求解TSP问题的基本思路即是遍历所有顺序,然后再遍历形成的解集中寻找最优解。因此整个问题的复杂度是随着节点个数增加随阶乘增长的。因此通过传统方法难以计算。而我们所希望的是通过模拟生物遗传进化的方法,找到难以解的全局最优解的近似。
我们试着探索如何将TSP问题套进遗传算法的框架中
首先,我们可以考虑概念的对应:
| 遗传概念 | 遗传算法 | TSP参数 |
|---|---|---|
| 个体优劣 | 评优函数 | 路径权和 |
| 基因构成 | 数据字串 | 遍历顺序 |
(我擦,说实话我之前以为比这还要困难些的欸)
那么,也许我们可以将TSP问题的一个解,即种群中的一个个体,表示为遍历地图顺序的字符串
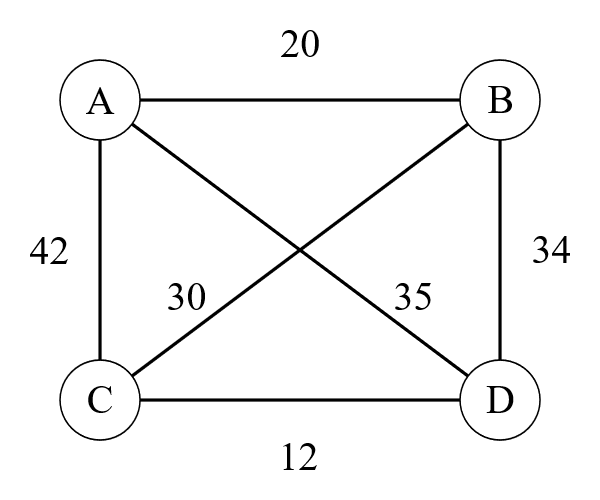
从wiki上捞了一张典型的图片,我们取一个解为[A, B, C, D]罢,那么他的个体优劣程度,即定义为20+30+12=62,即边权之和。那么我们继续去另一个个体[A, B, D, C],她(并没有歧视男同性恋朋友们的意思)则有边权20+34+12=66。
那么很显然优胜劣汰就是将这位可怜的姑娘del了
(剩下的男孩子们注定孤独一生)
停,不插科打诨了
一个很严肃的问题,交叉与变异应该怎么实现,如果仅仅是对染色体进行交叉互换的话,毫无疑问是难以满足路径约束的,但我们要怎么克服这个问题呢。。。陷入沉思;
变异
先谈相对简单的变异问题,我准备将其表示为随机碱基在其邻域(可设定范围罢)内的前后位移,这样可以约束防止离谱结果发生,同时可以作为逃离次优的根据。感觉实战效果会较之交换的方案更好。
交叉
由于自己创造力是在有限,这里俺参考了CSDN上的文章遗传算法中几种交叉算子小结
基于路径不重复的约束,主要可以做的有几种方法
- 为交换的基因创建映射关系,即Partial-Mapped Crossover (PMX)算子,并通过映射关系修改原有算子,从而使节点不重复出现
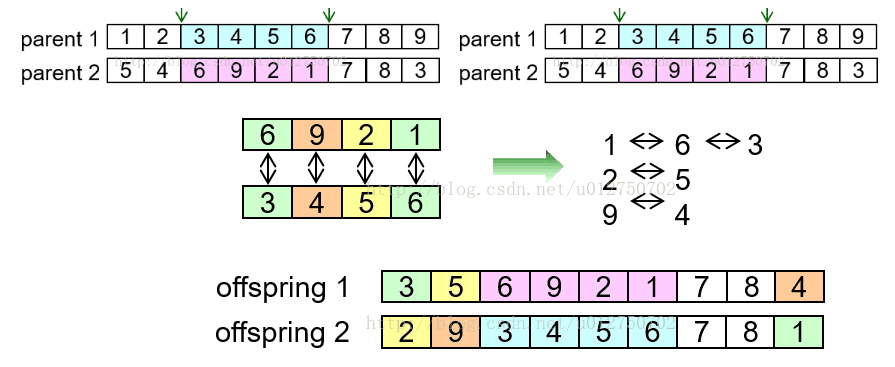
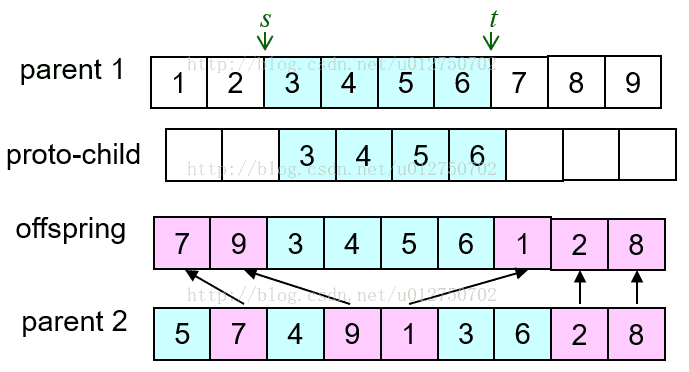
- Order Crossover (OX)算子,依据父本基因构建子代基因部分,然后用母本基因去除子代已有基因后的序列进行填充
- 有Position-based Crossover (PBX),Order-Based Crossover (OBX)算子,不用决定连续位点,不过思路都和OX算法类似(自行查阅
- 另外还有我最心水的Cycle Crossover (CX)算子 寻找父代基因的环,环外基因的全局互换并不会影响基因结构
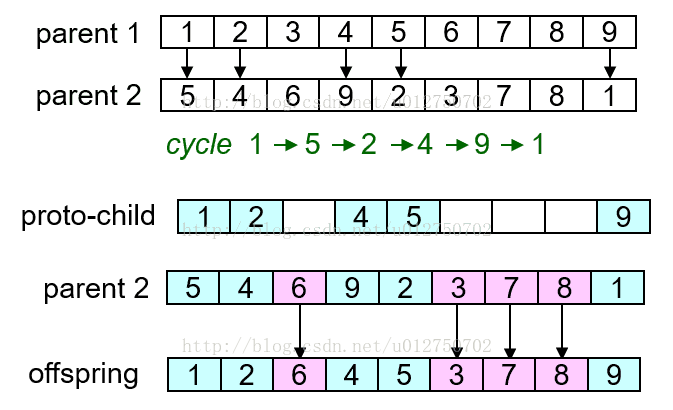
结果这么看下来,交叉未必有我们想象得那么复杂?
代码构建
那么让我们来考虑一下,要如何通过代码的形式构建遗传算法
个体构建
首先是考虑构建个体,及基因组,从最原始的世代而言,通常都是随机生成的序列。同时我们也不考虑较为复杂的基因结构,创建一个原始的基因类
class Unit {
public:
vector<int> Gene;
size_t Gene_length;
};基础构造
同时,给出最简单的随机构造算法
Unit(const size_t L, const bool init_ = true) : Gene_length(L) {
if (init_) randperm();
}
//生成随机基因
void randperm() {
vector<int> serial_num;
//生成序列,此处从1开始,视后续情况可改为从0开始
for (int i = 1; i <= Gene_length; ++i) serial_num.push_back(i);
//激情打乱
for (int i = Gene_length; i > 0; i--) {
int index = u(gen) % i;
Gene.push_back(serial_num[index]);
serial_num.erase(serial_num.begin() + index);
}
}繁殖交叉
// Cycle Crossover 交叉
Unit& CX_SIMPLE(const Unit& b) {
Unit* result = new Unit(Gene_length, false);
int nb = u(gen); //锁定随机碱基(位于基因1上
vector<int> temp;
while (count(temp.begin(), temp.end(), nb) == 0) {
//查找碱基在基因1上的位置
int iter = findPosVector(Gene, nb);
//储存当前碱基
temp.push_back(nb);
//指向下一碱基
nb = b.Gene[iter];
}
//对不在环内的基因进行交叉操作
for (size_t i = 0; i < Gene_length; i++)
if (count(temp.begin(), temp.end(), Gene[i]) == 0)
result->Gene.push_back(Gene[i]);
else
result->Gene.push_back(b.Gene[i]);
return *result;
}
// 用于查找元素位置的函数
int findPosVector(vector<int> input, const int number) {
vector<int>::iterator iter = std::find(
input.begin(), input.end(), number); //返回的是一个迭代器指针
if (iter == input.end()) {
return -1;
} else {
return std::distance(input.begin(), iter);
}
}遗传变异
// 偷懒用的变异
Unit& VG_SIMPLE_BACK() {
int index = u(gen);
Gene.push_back(Gene[index]);
Gene.erase(Gene.begin() + index);
return *this;
}种群构建
我们首先考虑种群需要有什么属性
首先,种群是个体的集合,也就是创建一个数组存放种群中所有的个体,其次便是种群容量,即确定种群中的个体数目,即种群容量,其次是交叉与变异的概率,从资料看来通常被设置为1和0.1。
同时,个体的价值也是由种群需要来定义的,我们在种群中需要建立价值判定函数,以及迭代进化函数
这是我构想的框架
class Group {
private:
//内部参数
//个体集合
vector<Unit> Indiv;
//价值评断
vector<float> Values;
//创建价值对,方便排序
vector<pair<Unit, float>> unit_value;
//优秀子代
Unit* best_u;
float best_v;
//外部参数
//基因长度(当前问题为城市数)
size_t Gene_length;
//种群容量
size_t Group_size;
//迭代次数
size_t Iter_times;
//交叉概率
float Cross_rate;
//变异概率
float Vg_rate;
//问题参数
vector<vector<int>> param;
public:
Group(size_t Gene_l, size_t Group_s, size_t Iter_t,
vector<vector<int>> param_t, float Vg_r = 0.1, float Cross_r = 1)
: Gene_length(Gene_l),
Group_size(Group_s),
Iter_times(Iter_t),
Cross_rate(Cross_r),
Vg_rate(Vg_r) {
best_u = new Unit(Gene_length);
//填充种群容量个长度为指定的个体
for (size_t i = 0; i < Group_size; i++) {
Unit unit(Gene_length);
Indiv.push_back(unit);
}
param = param_t;
Compute_Values();
for (size_t i = 0; i < Indiv.size(); i++) {
pair<Unit, float> temp = make_pair(Indiv[i], Values[i]);
unit_value.push_back(temp);
}
sort(unit_value.begin(), unit_value.end(), value_cmp);
best_u = new Unit(unit_value[0].first);
best_v = unit_value[0].second;
}
void Compute_Values() {}
void Evolution() {}
void Run() {}
};价值计算
对种群内个体价值的计算是相对简单的,直接丢函数啦
void Compute_Values() {
for (size_t i = 0; i < Indiv.size(); i++) {
float Value = 0; //当前个体价值
//检索参数表中两城市的距离,并累计加在个体价值上(价值越低的个体越好(?
for (size_t j = 0; j < Gene_length - 1; j++)
Value += param[Indiv[i].Gene[j] - 1][Indiv[i].Gene[j + 1] - 1];
Value +=
param[Indiv[i].Gene[Gene_length - 1] - 1][Indiv[i].Gene[0] - 1];
Values.push_back(Value);
}
}种群进化
那么接下来,我们考虑种群的进化
一个种群的进化拥有哪些指标呢,这是个好问题
先不考虑基因的寿命,仅仅考虑种群的隔代遗传
首先我们需要的是对种群进行一代繁殖,在这里我们可能会考虑价值较高(即values较低)的个体更高优先级同相似的个体进行繁殖,但是这也决定了种群是否需要经过两轮排序。由此经过交叉及变异,我们便能获得第一代子代。并将子代集合与父代集合进行并集处理,并淘汰价值较低,且超出了种群容量的个体。
给出我的实现?
static bool value_cmp(const pair<Unit, float>& a,
const pair<Unit, float>& b) {
return a.second < b.second; //根据second的值升序排序
}
void Evolution() {
//考虑婚嫁和繁殖
bool married[Group_size] = {0};
//只有前一半的人能主动婚嫁,假设只能找低于自己的(x
//等会儿改成正态分布的数据
for (size_t i = 0; i < Group_size / 2; i++) {
//讨老婆(?
// int wife = (i + rand() % (Group_size / 2)) % Group_size;
//天命
// int wife = rand() % Group_size;
int wife = abs(int(dis(gen) * Group_size / 2)) % Group_size;
//如果已婚
if (married[wife] || married[i]) continue;
//结婚登记(挪到前面来,避免了未婚先孕
married[i] = true;
married[wife] = true;
//繁殖,以及是否变异
if (rand() % 100 > Vg_rate * 100)
Indiv.push_back(Indiv[i].CX_SIMPLE(Indiv[wife]));
else {
Indiv.push_back(Indiv[i].CX_SIMPLE(Indiv[wife]));
Indiv[i].VG_SIMPLE_BACK();
}
}
//建立价值等级表单
Values.clear();
unit_value.clear();
Compute_Values();
for (size_t i = 0; i < Indiv.size(); i++) {
pair<Unit, float> temp = make_pair(Indiv[i], Values[i]);
unit_value.push_back(temp);
}
sort(unit_value.begin(), unit_value.end(), value_cmp);
//建立新生代数据库,落后于时代的勇士们依旧望着你
Values.clear();
Indiv.clear();
for (size_t i = 0; i < Group_size; i++) {
Values.push_back(unit_value[i].second);
Indiv.push_back(unit_value[i].first);
}
if (best_v > unit_value[0].second) {
best_u = new Unit(unit_value[0].first);
best_v = unit_value[0].second;
}
}运行/训练
void Run() {
int t = Iter_times;
while (t--) Evolution();
best_u->print();
cout << "best has value:" << best_v << endl;
}运行测试
距离矩阵是csdn上扒来的hhhh,之后准备在更棒的数据上跑个爽
int main() {
int test_times = 10;
const int city_num = 10; //城市数量
const int unit_num = 300; //群体规模
const float vg_pro = 0.1; //变异概率
const int gen_maxn = 500; //最大迭代数
//城市距离表,作为全局参数
int length_table[10][10] = {
{0, 1, 1272, 2567, 1653, 2097, 1425, 1177, 3947, 1},
{1, 0, 1, 2511, 1633, 2077, 1369, 1157, 3961, 1518},
{1272, 1, 0, 1, 380, 1490, 821, 856, 3660, 385},
{2567, 2511, 1, 0, 1, 2335, 1562, 2165, 3995, 933},
{1653, 1633, 380, 1, 0, 1, 1041, 1135, 3870, 456},
{2097, 2077, 1490, 2335, 1, 0, 1, 920, 2170, 1920},
{1425, 1369, 821, 1562, 1041, 1, 0, 1, 4290, 626},
{1177, 1157, 856, 2165, 1135, 920, 1, 0, 1, 1290},
{3947, 3961, 3660, 3995, 3870, 2170, 4290, 1, 0, 1},
{1, 1518, 385, 993, 456, 1920, 626, 1290, 1, 0}};
vector<vector<int>> vt;
int row = city_num;
int column = city_num;
//把城市距离邻接矩阵写入vector
for (int i = 0; i < row; i++) {
vector<int> tmp;
for (int j = 0; j < column; j++) tmp.push_back(length_table[i][j]);
vt.push_back(tmp);
}
//测试模型
vector<Group> rua;
int t = test_times;
while (t--) rua.push_back(Group(city_num, unit_num, gen_maxn, vt, vg_pro));
for (size_t i = 0; i < test_times; i++) rua[i].Run();
system("pause");
return 0;
}我得去交作业了(?
Comments NOTHING