
我们都是读过高中英语的人,众所周知变形金刚=transformer(啊这
最近被导师安排课题了,安排得明明白白,老CV被迫接触NLP
我还是老咸鱼了。为了不被导师单杀,姑且作为入门和复建,尝试性地做一下最热门且最实用的Transformer结构复现,过程中主要参考了以下文章
- SangrealGao:从 0 开始学习 Transformer
- 罗周杨:Transformer的PyTorch实现
- Jay Alammar:illustrated transformer
- TensorFlow:理解语言的 Transformer 模型
在进行具体构建网络的工作前,我们可以对整个Transformer网络的结构进行考虑。
如上图所示的是网络的概述概览,感谢Jay Alammar的工作,我们自顶向下描述Transformer的结构。
其约莫是由九个不同层次的结构组成的。
- Transformer
- Decoder(DecoderLayer*N)
- PositionalEncoding
- MultiHeadAttention
- ScaledDotProductAttention
- PositionalWiseFeedForward
- Encoder(EncoderLayer*N)
- PositionalEncoding
- MultiHeadAttention
- ScaledDotProductAttention
- PositionalWiseFeedForward
- Decoder(DecoderLayer*N)
具体实现咱先别谈,我们来说说其中的每个机制是做什么的
由输入信息经过的结构开始描述,可能会有一点抽象
位置编码系统PositionalEncoding
描述输入单词之间的距离结构,用于和词嵌入编码进行组合,使距离较远词汇相关性弱
点积注意力机制ScaledDotProductAttention
使用乘法加权周围单词特征取得自注意力,获取编码权重
多头注意力机制MultiHeadAttention
同时使用多组权重的点积注意力机制进行判断,组合特征
位置式前馈网络PositionalWiseFeedForward
双层前馈全连接神经网络,重编码权重注意力及位置信息
编码器Encoder
多层(多头注意力+前馈网络)组合,取得深度输出
解码器Decoder
多层引入编码信息的注意力+前馈网络
变形金刚(?
编码器与解码器的组合,从词特征解码至语料库,生成新词
网络的构建
我们从头开始去考虑transformer网络的细节,并逐步考虑如何完善这个系统。
句子编码
transformer作为一个基于自然语言处理的模型,其第一要点便是词汇含义的表达,这门学问便是单词语料的向量化,即embedding
在这项工作里,我们要决定模型总的文字编码向量长度,同时要把一段句子转化为一个大小为的矩阵。这其中包含了两个操作,其一是对句子中的单词进行向量化,长度为。其二是一组关于引导的位置编码向量,由以下方法构建。
位置编码
这一步,我们需要对输入单词之间的距离进行表示
在Transformer中所使用的位置编码(positional encoding)有如下三角函数形式定义
其中为词嵌入的维数,另外有辅助计算各维度向量值,有奇数维由cos编码,偶数维由sin编码,另外pos表示各个位置向量,有表示pos位置向量的维位置编码向量。在通用模型中,一般把设置为512
有意思的是,当求位置的向量时,可以转化为对的线性表示,由三角函数组合公式有
好吧但是我还是不清楚为啥要这样表示
def get_angles(pos, i, d_model):
return pos / np.power(10000, (2 * (i//2)) / np.float64(d_model))
def positional_encoding(position, d_model):
# np.newaxis的作用为将数组化成矩阵形式
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# 修改偶数索引
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
# 再次增加维度
pos_encoding = angle_rads[np.newaxis, ...]
return torch.from_numpy(pos_encoding)
# print(positional_encoding(10,12))
另外,此处的距离显然是可以替换的,未来我会将其使用于图结构信息的编码中,重构距离编码,或许能参考Distance Encoding – Design Provably More Powerful GNNs for Structural Representation Learning一文所提出的距离编码
为了方便pytorch网络模型的构造,参考了罗周杨一文中的层式实现
# 位置编码模块
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_l):
super(PositionalEncoding, self).__init__()
"""
d_model:模型维度,即编码总长度
max_l:最大文本序列长度,用于控制缓存
"""
# 构造Pe矩阵
position_encoding = np.array([[pos / np.power(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)] for pos in range(max_l)])
# 偶数列使用sin,奇数列使用cos
position_encoding[:, 0::2] = np.sin(position_encoding[:, 0::2])
position_encoding[:, 1::2] = np.cos(position_encoding[:, 1::2])
# 进行PAD操作,难以理解的部分,可能是由于句子初始化并非从0开始
pad_row = torch.zeros([1, d_model])
position_encoding = torch.cat((pad_row, torch.from_numpy(position_encoding)))
# 使用词嵌入方法进行封装,设定
self.Pe = nn.Embedding(max_l + 1, d_model)
self.Pe.weight = nn.Parameter(position_encoding, requires_grad=False)
def forward(self, input_len):
# 通常input_len的最大值被固定为最大可感长度,128、256或512?
max_l = torch.max(input_len)
tensor = torch.cuda.LongTensor if input_len.is_cuda else torch.LongTensor
# 对每一个序列的位置进行对齐,在原序列位置的后面补上0
# 这里range从1开始也是因为要避开PAD(0)的位置
input_pos = tensor(
[list(range(1, l + 1)) + [0] * (max_l - l) for l in input_len])
# 返回单句位置编码向量,后与词嵌入向量拼贴
return self.Pe(input_pos)
在该实现中,模块由将通过输入模型最大文本序列长度及模型编码维度生成特定的词嵌入偏移向量,以应用于每个句子(在Encoder部分组合中可以保存单次前向传播结果,减少重复运算)
词汇嵌入
词嵌入部分相对比较简单,由单行代码完成。
self.Em = nn.Embedding(vocab_size + 1, d_model, padding_idx=0)
out = self.Em(x) * (self.d_model ** -0.5)
其中由论文要求引入因子进行归约化,然而莫得理由。
*Mask
另外,作为补充我们可以谈谈遮罩,在transformer模型中我们会使用到两种遮罩,分别为padding_mask以及sequence_mask,其中padding mask多用于点积注意力的获取中,而sequence mask用于decoder中的前自注意部分
padding mask
用于遮挡面对空余位置注意力的
def padding_mask(seq_k, seq_q):
# seq_k和seq_q的形状都是[B,L]
len_q = seq_q.size(1)
# `PAD` is 0
pad_mask = seq_k.eq(0)
# shape [batch_size, L_q, L_k]
pad_mask = pad_mask.unsqueeze(1).expand(-1, len_q, -1)
return pad_mask
sequence mask
该序列遮罩用于为decoder遮挡未来信息,因此构造三角矩阵至于时间步遮挡序列
def sequence_mask(seq):
batch_size, seq_len = seq.size()
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.uint8),
diagonal=1)
mask = mask.unsqueeze(0).expand(batch_size, -1, -1) # [B, L, L]
return mask
点积自注意机制
自注意力机制是transformer网络的核心机制,通过文献的阅读我们可以了解到,transformer模型中元素之间的注意力由以下要素构成:词汇表示的相近程度及词语位置的相邻程度。并通过注意力的叠加获取词汇的深层语义
注意力的计算在transformer中被表现为以下形式
我们呈现出的注意力表现为输入词汇对应三组向量的函数,分别为
- Q:请求向量 query
- K:键向量 key
- V:值向量 value
可以这样对此三组向量进行理解:对于输入序列中的两个元素,可以通过请求向量与键向量的匹配确定其语义间关联,在softmax压缩获取对应权重后与词向量进行加权求和,从而获得最终注意力的值。对于整组序列数据,使用矩阵相乘进行计算,有如下计算图
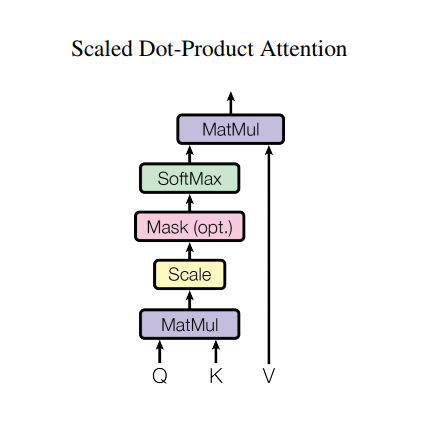
其中等比缩放Scale过程为防止梯度消失,参考引文讨论部分:
为什么要按比缩放Scale:这是原论文中的一个推测——如果输入的Q,K维度过大,则会导致点积后的结果很大softmax函数有一个特点,当输入的x越大,其梯度会趋近于0。这对于基于梯度下降法的优化非常不利。(这个是一个有根据的推测:假设q和k都是独立的随机变量,那么q乘上k是均值的0方差为$d_k$的。除以深度的平方根,可以让方差为 1)
另外此处的mask操作是可选的,用于设计忽略部分输入(然而在图像用transformer中应该没啥用)
暂且不谈三组向量的获得方式,考虑输入集群,我们构造向量化的注意力批量计算形式
def attention(q, k, v, mask = None):
"""
要求参数符合下列形态标准:
q: 请求 == (..., seq_len_q, depth)
k: 键 == (..., seq_len_k, depth)
v: 值 == (..., seq_len_v, depth_v)
mask: == (..., seq_len_q, seq_len_k)
"""
# 转置k矩阵相乘,QK^T == (..., seq_len_q, seq_len_k)
matmul_qk = torch.matmul(q, k.transpose(k.dim()-2,k.dim()-1))
# 编码长度
sqrt_dk = math.sqrt(q.shape[-1])
scaled_qk = matmul_qk / sqrt_dk
if mask is not None:
scaled_qk += (mask * -1e9)
# 在seq_len_k轴上进行归一化,获取注意力权值表
attention_weights = torch.softmax(scaled_qk, dim=-1)
# 输出对于每个输入词自注意后的值depth_v维词嵌入向量
# (..., seq_len_q, depth_v)
out = torch.matmul(attention_weights, v)
return out, attention_weights
同样的,我们可以将该注意力工作改写成pytorch中的层运算:
class ScaledDotProductAttention(nn.Module):
def __init__(self, dropout=0):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(dropout)
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None):
"""
要求参数符合下列形态标准:
q: 请求 == (..., seq_len_q, depth)
k: 键 == (..., seq_len_k, depth)
v: 值 == (..., seq_len_v, depth_v)
mask: == (..., seq_len_q, seq_len_k)
"""
# 获取深度
depth = torch.tensor([q.shape[-1]], dtype=torch.float32)
# 转置k矩阵相乘,QK^T == (..., seq_len_q, seq_len_k)
# 默认缩放$\sqrt{d_k}$
attention_weights = torch.matmul(q, k.transpose(-2,-1)) / torch.sqrt(depth)
if mask is not None:
attention_weights = attention_weights.masked_fill_(mask, -np.inf)
attention_weights = self.dropout(self.softmax(attention_weights))
return attention_weights.matmul(v), attention_weights
多头注意力机制
我们重新考虑transformer中三组向量的构建。通过下列图示,我们可以更好地理解transformer的机制,即对于某个输入的词汇,此三组向量均由一组矩阵同原始词嵌入相乘构建。其机理同样可以表示为三组全连接神经网络,从而方便我们模型的构建。使用该方法将词汇原始的空间嵌入编码为可通过学习改变的请求、键、值。
![]()
对应前一节的逐步计算方式,有下图进行梗概:

我们可以简单的理解为在当前注意力头中,单词的值由与单词含义相关的词汇的value相叠加。
多头注意力的实质是,通过构建多个自注意力机制及其权重来学习更加复杂的关联信息。而我们希望将构建所有注意力头的输出,通过再一次的线性变换,融合为统一的输出
我们通过多头注意力机制统括整个注意力模型的结构
def __init__(self, d_model=512, head_num=8, dropout=0):
"""
head_num: 表示注意力机制的总头数,默认为8
d_model:表示词嵌入的维数,默认512维映射给了8个头每个头64维
"""
assert d_model % head_num == 0
super(MultiHeadAttention, self).__init__()
self.head_num = head_num
self.d_model = d_model
# 对于每个头的编码维数
self.depth = d_model // head_num
self.Wq = nn.Linear(self.d_model, self.depth * self.head_num)
self.Wk = nn.Linear(self.d_model, self.depth * self.head_num)
self.Wv = nn.Linear(self.d_model, self.depth * self.head_num)
self.Fc = nn.Linear(self.d_model, self.d_model)
self.Attention = ScaledDotProductAttention(dropout)
self.Dropout = nn.Dropout(dropout)
self.Norm = nn.LayerNorm(self.d_model)
def forward(self, q, k, v, mask=None):
# 实际输入三组向量可能相同
# 引入残差连接
res = q
batch_size = q.shape[0]
# 线性编码输入x后按头拆分
q = self.Wq(q).view(batch_size * self.head_num, -1, self.depth)
k = self.Wk(k).view(batch_size * self.head_num, -1, self.depth)
v = self.Wv(v).view(batch_size * self.head_num, -1, self.depth)
if mask is not None:
mask = mask.repeat(self.head_num, 1, 1)
out, attention = self.Attention(q, k, v, mask)
# 将按头拆分的注意力合并
out = out.view(batch_size, -1, self.depth * self.head_num)
out = self.Norm(res + self.Dropout(self.Fc(out)))
return out, attention
其中将每个注意力头统一初始化为一个大矩阵,然后通过向量reshape的方式分别计算,并进行逆操作拼合注意力,从而完成整个多头注意力的构建
位置式前馈神经网络
该神经网络表现为一组全连接层,位于多头注意力机制上方,用于重新编码多头注意力,完成encoding
其数学表现如下
可以使用1*1卷积核对全连接层进行模拟,从而方便操作。
其结构也相当简单
class PositionalWiseFeedForward(nn.Module):
def __init__(self, d_model=512, dff=2048, dropout=0):
super(PositionalWiseFeedForward, self).__init__()
self.W1 = nn.Conv1d(d_model, dff, 1)
self.W2 = nn.Conv1d(dff, d_model, 1)
self.Dropout = nn.Dropout(dropout)
self.Norm = nn.LayerNorm(d_model)
self.Relu = nn.ReLU()
def forward(self, x):
out = self.Relu(self.W1(x.transpose(-1,-2)))
out = self.W2(out).transpose(-1,-2)
out = self.Norm(x+self.Dropout(out))
return out
有了上述结构,我们完成了transformer中所需的所有子结构
随后,我们可以基于上述实现的子结构对编码器、解码器,乃至完整的transformer结构进行构造
编码器
![]()
编码器相对解码器结构会更简单一点,在LayerNorm已经被集成在多头注意力机制及前馈神经网络中的前提下,我们能用少量的代码完成编码器层的构建
class EncoderLayer(nn.Module):
def __init__(self, d_model, head_num, dff, dropout=0):
super(EncoderLayer, self).__init__()
self.Att = MultiHeadAttention(d_model, head_num, dropout)
self.ffn = PositionalWiseFeedForward(d_model, dff, dropout)
def forward(self, x, mask=None):
out, attention = self.Att(x, x, x, mask)
out = self.ffn(out)
return out, attention
并通过编码器层的叠加及初始化的输入词嵌入完成输入端的编码器结构
# 编码器
class Encoder(nn.Module):
def __init__(self, vocab_size, max_l, layer_num=6, d_model=512, head_num=8, dff=2048, dropout=.0):
"""
vocab_size: 语料库大小
max_l: 最大单句长度
layer_num: 编码器总层数
d_model: 词嵌入维数
head_num: 多头注意力维数
dff: 前馈隐藏层数
dropout: 跳跃连接概率
"""
super(Encoder, self).__init__()
self.d_model = d_model
self.layer_num = layer_num
self.head_num = head_num
self.dff = dff
self.Em = nn.Embedding(vocab_size + 1, d_model, padding_idx=0)
self.Pe = PositionalEncoding(d_model, max_l)
self.Encoderlayers = nn.ModuleList(
[EncoderLayer(d_model, head_num, dff, dropout) for _ in range(layer_num)])
def forward(self, x, seq_len):
# 完成词嵌入
out = self.Em(x)
out *= torch.sqrt(torch.FloatTensor([self.d_model]))
out += self.Pe(seq_len)
# 构造mask
mask = padding_mask(x, x)
# 逐层计算注意力
attentions = []
for encoder in self.Encoderlayers:
out, attention = encoder(out, mask)
attentions.append(attention)
return out, attentions
解码器
解码器的结构相对于编码器会稍微复杂一些

其中由两组多头注意力构成,并且注意力同时受到了输入及先前输出的影响,从而完成整个注意力过程,值得注意的是,解码器接受来自encoder的键值,并使用来自前段编码的请求,从而达成通过已知信息请求未知信息的效果
class DecoderLayer(nn.Module):
def __init__(self, d_model, head_num, dff, dropout=0):
super(DecoderLayer, self).__init__()
self.self_Att = MultiHeadAttention(d_model, head_num, dropout)
self.ende_Att = MultiHeadAttention(d_model, head_num, dropout)
self.ffn = PositionalWiseFeedForward(d_model, dff, dropout)
def forward(self, x, encoded, self_attn_mask, mask=None):
out, self_att = self.self_Att(x, x, x, self_attn_mask)
out, ende_att = self.ende_Att(out, encoded, encoded, mask)
out = self.ffn(out)
return out, self_att, ende_att
其中输入x是前置层/前置输出的编码向量,而encoded是完成输入编码后的高层语义信息,整个网络每次仅通过完整输入和前一步输出的短句预测下一个词汇,仅当开始第一步预测时存在无中生有,并且解码器对应的词嵌入为目标域上的嵌入,与输入存在不同的嵌入方式,以下为解码器结构的构造
class Decoder(nn.Module):
def __init__(self, vocab_size, max_l, layer_num=6, d_model=512, head_num=8, dff=2048, dropout=.0):
super(Decoder, self).__init__()
self.d_model = d_model
self.layer_num = layer_num
self.head_num = head_num
self.dff = dff
self.Em = nn.Embedding(vocab_size + 1, d_model, padding_idx=0)
self.Pe = PositionalEncoding(d_model, max_l)
self.Decoderlayers = nn.ModuleList(
[DecoderLayer(d_model, head_num, dff, dropout) for _ in range(layer_num)])
def forward(self, x, encoded, seq_len, mask=None):
out = self.Em(x)
out *= torch.sqrt(torch.FloatTensor([self.d_model]))
out += self.Pe(seq_len)
self_attention_padding_mask = padding_mask(x, x)
seq_mask = sequence_mask(x)
self_attn_mask = torch.gt((self_attention_padding_mask + seq_mask), 0)
for decoder in self.Decoderlayers:
out, _, _ = decoder(out, encoded, self_attn_mask, mask)
return out
其中TODO的部分为解码器特化的遮罩,有时我们希望解码器仅关注前部信息所以会构建特殊的遮罩以改善效果,但是我在此处并没有进行实现。
Transformer
最后,我们能将encoder和decoder组装,取得完成的transformer
class Transformer(nn.Module):
def __init__(self, i_vocab_size, i_len, o_vocab_size, o_len, layer_num=6, d_model=512, head_num=8, dff=2048, dropout=.0):
super(Transformer, self).__init__()
self.Encoder = Encoder(i_vocab_size, i_len, layer_num, d_model, head_num, dff, dropout)
self.Decoder = Decoder(o_vocab_size, o_len, layer_num, d_model, head_num, dff, dropout)
self.Fc = nn.Linear(d_model, o_vocab_size)
self.Softmax = nn.Softmax(dim=-1)
def forward(self, raw, len_r, tar, len_t, mask=None):
if mask is None:
mask = padding_mask(raw, tar)
out, _ = self.Encoder(raw, len_r)
out = self.Decoder(tar, out, len_t, mask)
out = self.Softmax(self.Fc(out))
return out
可以使用以下代码进行测试√
trans = Transformer(8500,62,8000,26)
raw = (torch.rand(64,62)*5000).long()
tar = (torch.rand(64,26)*5000).long()
len_r = (torch.ones(raw.shape[0]) * raw.shape[1]).int()
len_t = (torch.ones(tar.shape[0]) * tar.shape[1]).int()
print(raw)
print(tar)
o = trans(raw,len_r,tar,len_t)
print(o.shape)
print(o)
Comments NOTHING