
AnimationGPT —— 一个AIGC游戏动画资产创建工具
顺手翻到了这个项目最初启动的时间,已经是一年四个月前了,在AIGC尚未风靡之前开启的探索,在第一轮AIGC浪潮稍显落寞之时才落定。
(姑且也不算落定,还有好多真正值得推进的探索方兴未艾)
这篇文章是和贝伦、香鱼同学一同写就的,但这并非最终的publish版本,更偏向一个个人的存档
最终版本会被更新到贝伦的知乎账号和项目的官方页面上(虽然现在域名都还没过审)
(两年入行游戏之前,还在拜读那篇经典文章,两年后就一起写东西了,还挺奇妙的)
接下来希望还有机会进一步探索,包括优化数据集,通过RWKV加持使其获得更复杂的基于需求生成能力;也包括改良动作编码器,引入 SAN 等框架实现动作模型的大一统。
不过按我这三天打鱼两天晒网的性子,谁知道呢,总之欢迎大伙紧俏关注后续的文章捏!
摘要
随着人工智能领域的迅速发展,对于高质量、风格化的动作数据集的需求日益增长。目前,学术界普遍主要使用的只有一个两年前制作的包含 14.6k 动作的开源动作数据集 HumanML3D。由于动作数量稀少、风格单一化生活化,这极大限制了研究的深度与广度。为了解决这一问题,我们独立制作并开源了一个全新的、精心标注的、有 14.8k 动作的风格化战斗动作数据集 CombatMotion Dataset(以下简称"CM 数据集")。
传统上,描述一个战斗动作是非常困难且模糊的工作,这在模型训练和自动化生成中会导致语义理解方面的不一致性。为了克服这一挑战,我们通过规范标准,划分出八大类战斗动作描述维度,并通过逐类建立丰富词库的方式,提高了标注效率和一致性。
通过对近期各类科研成果的综合比较和新数据集的尝试性训练,我们发现 MotionGPT 框架在语义理解和一致性方面表现最佳。基于 MotionGPT 框架和 CM 数据集,我们成功训练出了一个能够生成高质量战斗动作的文本-动作模型,并撰写了基于 Maya 的动作重定向脚本,将学术界常用的 SMPL 骨骼 转换为工业界广泛使用的 BVH 格式。
综上,我们实现了一整套可复制的工作流规范,包括数据提取、数据标注、动作重定向、训练、推理和接入商业引擎的全过程。这一突破不仅为运动数据集的丰富化和科研工作的拓宽和深入提供了坚实的基础,也为未来的动作生成技术的发展和商业应用开辟了新的道路。
我们希望这项工作能激发更多的研究者、开发者和企业共同探索这一未充分挖掘的领域,共同推动人工智能和人类动作生成实用化的发展。
早期调研
从现在开始回顾,2022 年无疑是生成式 AI 元年,这一年间,从图像到文本的生成,从 Diffusion 到 ChatGPT。随着一众亮眼产品的出现,AI 从科研领域未来可期的明灯,变成了切实能影响工作生产的重要工具。
对游戏行业而言,第一次注意到 AI 的能力还是 2022 年的 10 月。NovalAI 的爆火和泄露,让早在 8 月发布的 Stable Diffusion 从二次元的角度真正切入大众的视野,而与之相关一众新技术的提出,也让 Diffusion 这一架构成为生成式 AI 领域最炙手可热的课题。
人们不自觉地设想,Diffusion 除了用于生成图片,还能生成哪些更多东西。
当然,上述趋势在学界更早地被洞见。因此,当我们偶然设想到我们能否用 Diffusion 的架构生成诸如动作、动线等序列内容时,我们发现了不久前提出的[https://arxiv.org/abs/2209.14916]一文。其很好地结合了 Diffusion 的扩散生成思路和 Transformer 的序列预测能力,将其运用到了人类动作序列的生成当中。呈现了极好的语言指导动作生成效果。
这使得我们开始构想,可以遇见该生成工作流像生成图像一般被引入游戏生产中的未来——直到我们发现该领域一直止步于科研境地的真实原因。
正如不温不火的 GPT-3,在经过微调后形成引爆生成式 AI 的 ChatGPT 一样,我们可以认为,AI 实用化有着三驾马车,同时也是三座大山 —— 算力、算法、数据。
其中算力服从于摩尔定理的客观规律,算法依赖一代代科学家的研究,而数据却别无可依。除了想创造新的领域另辟蹊径发论文的人,或是立志推动行业科研发展的开源主义者推出的数据集,数据往往是最匮乏、最难取得的资源。
如图像、文本、声音此类资源,尚且能依据其原生性,有着统一的数据规范,相对容易采集。若是进一步考虑那些人为规定的二级数据,其筹备难度可想而知 —— 显然,动作/动画就是这样一个领域。
当前,动作生成的困境在于,过于匮乏的数据,以及匮乏数据中进一步分散的表示方法。
- 在工业界,动画师通过 FBX 乃至其它高级文件储存动画信息,通过记录不同名字和连接关系的骨骼其旋转与位移,并基于此传递动画文件和合作
- 在工业学术界(以 Siggraph 为首的前沿图形学),习惯使用 BVH 等数据结构高效储存各种运动信息和基本骨架,专注于对数据本身的学习和处理
- 在学术界(这里指的主要是计算机视觉学术界),则乐于基于 SMPL 系的既有轮子和数据进行开发,捉摸算法模型本身的性能,并以打榜发论文为首要追求
而我们发现的 MDM 这一工作,其则是基于视觉学界使用的 SMPL 体系,而这一体系下,可用的数据甚至只有一则数据集 [https://github.com/EricGuo5513/HumanML3D]
这是一则描述了各色日常动作的动捕数据集,其固然存在一定丰富性以支撑该领域的科研。但一旦涉及更多、稍有离群的动作,其就已经难以代表生产中的实际需求了。
尽管当前动作数据的基础设施尚不完善,我们对生成式人工智能技术的未来发展仍持乐观态度。依据我们掌握的高质量游戏领域动画资源和对于近期各类算法框架的广泛研究。我们希望即使在技术的全面成熟之前,这些早期成果也能为该领域的进步做出贡献。
于是,我们尝试展开了如今的工作,并取得了相当有趣且富有成效的结果,将在下文中详细讨论。
数据集制作
在我们的文本生成动作相关研究工作中,数据集的制作是一个至关重要的环节。相较于自然语言及图片数据在内容上的丰富与多样,在格式上的易用与统一。动作数据无论是在学术抑或工业领域,都呈现出一种极度蛮荒原始的形态。
套用 MoFusion 项目的一句话
On the other hand, motion datasets are notorious for not following the same convention, due to the specific needs of their creators. In particular, each dataset can use a skeleton with a different number of joints, different joint indices, as well as a different default pose such as the T-pose, the A-pose, or any other poses.
#另一方面,动作数据集是臭名昭著的,因为创造者的特定需求,他们并不遵循相同的约定。特别是,每个数据集都可以使用具有不同关节数量、不同关节索引的骨骼,以及不同的默认姿势,如 T 型姿势、A 型姿势或其他任何姿势。
上述段落仅提到了因骨骼拓扑结构不统一而导致的研究困难,更进一步的难题,在于当前严重缺乏精心标注、风格多样、数量足够的动作数据。
在 2019 年,由光学动捕方法制作的包含 11k 日常人体活动动作的 AMASS 数据集。在 2022 年,EricGuo5513 将这一数据集结合其他拓展为 14.6k 动作,并且进行粗标注后开源,这就是当前学术界最常用的动作数据集—— HumanML3D。
但不幸的是,这个数据集的数量、质量、风格依然不满足我们"面向动画师"的需求。第一点源于动作数据本身,风格过于日常化,且因为是无需求面向的动捕动作,所以不会出现更自由,更有表现力但是人体其实无法做出的动作;第二点源于标注的不准确性和随意性,当我们面向人类提出动画诉求时,常会以动作类型 → 手性 → 姿态 → 动势 → 四肢,这样由粗到细的顺序去描述一个动作,过于日常的语言风格不利于模型在训练过程中建立自然语言 → 动作映射。
基于上述两个认识,我们决定从头开始,独立制作一套以高质量战斗动作和符合动画师需求习惯精标注的数据集。在这个过程中我们建立了完整的数据提取 → 重定向 → 规范标注 → 润色整合的制作框架,为日后继续拓展任意多的新数据打下了坚实的基础。
我们首先从高质量作品(比如 Maxiamo)的资源中提取所需的、战斗风格为主的动作数据,这些数据包括了各种动作的细节信息。
其次,为了统一动作数据的标准,我们选取了 SMPL(Skinned Multi-Person Linear Model)骨骼作为基底,这一骨骼模型发布于 2015 年,是一个线性可叠加的通用人体蒙皮骨骼,带有 10 个维度的形状参数(shape parameters)和 24×3 维度的姿态参数(pose parameters)。设定的基模版是通过统计大量的真实人体,制作模型后取平均值得到的形状。通过对主要形状成分(Principal Shape Components)或者称之为端点偏移(Vertex Deviations)进行线性组合,并且在基模版上进行叠加,我们就形成了静默姿态的模型。是目前最常用于学术科研界的人体骨骼拓扑结构。
我们利用 MotionBuilder 对提取的动作数据进行了骨骼重定向,将其全部重定向至 SMPL 骨骼模型,这一步骤确保了数据的一致性和可复用性。
随后,我们进行文件格式的转换,具体是将 fbx 格式的动作数据利用 MayaScript 转换为 npy 格式,以便于后续处理。
在动作数据的标注过程中,我们细化了总共八个字段分类,包括动作类型、武器类型、攻击类型、方位类型、力量感形容词、速度感形容词、模糊形容词以及姿势形容句。这些分类维度不仅涵盖了动作数据的各个方面,也为后续的数据分析和模型训练提供了丰富的标注信息,制定了完整的标注规范。下面将介绍每个字段对应的表征模式:
- 动作类型——对于任意类型动作有效,表征动作模式的大类归属
- 武器类型——对于战斗类型动作有效,表征动作对应的武器模组类型
- 攻击类型——对于战斗类型动作有效,表征动作对应的手性及攻击强度和攻击连携态
- 方位类型——对于任意类型动作有效,表征动作的根骨骼运动方向
- 力量感形容词——对于任意类型动作有效,表征动作姿态轻柔抑或沉重的程度变化
- 速度感形容词——对于任意类型动作有效,表征动作姿态迟缓抑或迅捷的程度变化
- 模糊形容词——对于任意类型动作有效,表征动作的引起的感受与情绪
- 姿势描述句——对于任意类型动作有效,贴合生活化的自然语言,表征动作触发后四肢的运动形态
为了更精确地反映战斗策划的需求,我们根据策划提出的习惯用语,对前 7 种字段各自建立了一个丰富的词库,依照映射表进行人工标注。为了进一步提升标注的质量和自然性,我们还利用了 ChatGPT 进行标注润色,通过自然语言处理技术优化了标注内容的表达方式。
标注词库见下表:
| Motion Type | Weapon Type | Attack Type | Direction | Power Descriptor | Speed Descriptor | Fuzzy Descriptor |
|---|---|---|---|---|---|---|
| Idle | Bare Hand | Left-Handed | In-Place | Light-Weighted | Swift | Piercing |
| Get Hit | Sacred Seal | Right-Handed | Towards Left | Steady | Relative Fast | Slash |
| Death | Fist | One-Handed | Towards Right | Heavy-Weighted | Uniform Speed | Blunt |
| Switch Weapon | Claw | Two-Handed | Forward | Powerless | Relative Slow | Stunned |
| Movement | Great sword/Colossal sword | Dual Wielding | Backward | Powerful | Slow | Unarmed attack |
| Dodge | Curved Sword/Curved Greatsword | Light Attack | Left Front | Straightforward | First slow then fast | Featherlike |
| Weapon Attack | Spear | Heavy Attack | Right Front | Charged | First fast then slow | Sluggish |
| Spell | Dagger | Charging | Left Rear | Light Stagger | Cleanly | Uninhibited |
| Use Item | Straight Sword | Charged Heavy Attack | Right Rear | Stagger | Sloppy | Unwilling |
| Interaction | Thrusting Sword | Roll Attack | Mid-Air | Heavy Stagger | Instant Recovery | Smooth and Coherent |
| Be Thrown | Katana | Run Attack | Falling | Recovery | Rigid | |
| Social Action | Axe/Great Axe | Backstep Attack | Be Launched to Air | Slow Recovery | Wide Open | |
| Pose | Hammer/Great Hammer | Junp Attack | Knocked Down | Charging | ||
| Block/Guard | Flail | Fall Attack | Accumulating strength | |||
| Ride | Whip | Crouch Attack | Instant Burst | |||
| Hanging Movement | Staff | Shoot | Devout | |||
| Swimming | Torch | Kick | Crazy | |||
| Falling | Hand Lantern | Attack Bounce-off | Dangling | |||
| Eavesdrop | Ballistae | Deathblow | Juggling | |||
| Grappling Hook | Reaper | Holding | Somersaulted | |||
| Shinnobi Prosthetic | Halberd | Null | Dancing | |||
| Bow | Quickstep Attack | Roundabout | ||||
| Shield | Air Attack | Crawling | ||||
| Crossbow | Chasing Slice | Respect | ||||
| Twinblade | Hanging Attack | Provocation | ||||
| Shuriken | Attack underwater | Angry | ||||
| Flame Vent | Stomp | Cheerful | ||||
| Firecracker | Combat Art | Depressed | ||||
| Sabimaru | Transforming Attack | Gaunt | ||||
| Umbrella | Weak | |||||
| Mist Raven | Painful | |||||
| Fan | Nervous | |||||
| Finger Whistle | Relaxing | |||||
| Gorgeous | ||||||
| Elegant | ||||||
| Panicked | ||||||
| Sudden | ||||||
| Awkward | ||||||
| Weird |
接下来,我们对标注词性进行了划分,以便于模型更好地理解和处理标注信息。基于此,最终制作得到了包含 14.8k 个动作、14.8k 条标注的战斗风格动作数据集——CombatMotionRaw Dataset(CMR Dataset),目前该数据集已开源在我们的 GitHub 项目中。
此外,我们反复尝试了训练集和测试集的不同切割方式,根据训练结果的反馈对数据集的大小和标注内容进行了数次调优,最终得到了精制作数据集 CombatMotionProcessed Dataset(CMP Dataset),目前该数据集已开源在我们的 GitHub 项目中。它拥有 8.7k 个动作数据和 26.1k 标注文本。这个数据集最终确保了模型训练的有效性和最优化。
当然的,在数据集制作的过程中,我们也面临一些不足之处,比如无法得到指定动作的风格、限制动作帧数或替换不同的方案的需求指令,这让原本预期“与 AI 顺畅对话”的目标难以达成。为了克服这些挑战,我们下一步计划寻找实际落地的动作需求作为标注,并持续扩大数据集的规模,以期达到更高的研究和应用价值。
模型选取
随着数据集制备工作的妥善进展,在时间跨度上,也出现了一系列值得参考的新工作,他们多数都被纳入了我们选择生成方案的考量。其中除 MDM 的外,最值得讨论还有 MLD 和 MotionGPT
- GuyTevet/motion-diffusion-model: The official PyTorch implementation of the paper "Human Motion Diffusion Model" (github.com)
- ChenFengYe/motion-latent-diffusion: [CVPR 2023] Executing your Commands via Motion Diffusion in Latent Space, a fast and high-quality motion diffusion model (github.com)
- OpenMotionLab/MotionGPT: [NeurIPS 2023] MotionGPT: Human Motion as a Foreign Language, a unified motion-language generation model using LLMs (github.com)
这三份工作在技术思路上一脉相承,同时也有着各自的优缺点及特点。
由此出发,我们希望通过讨论其异同,展望动作生成工作后续发展的可能性。
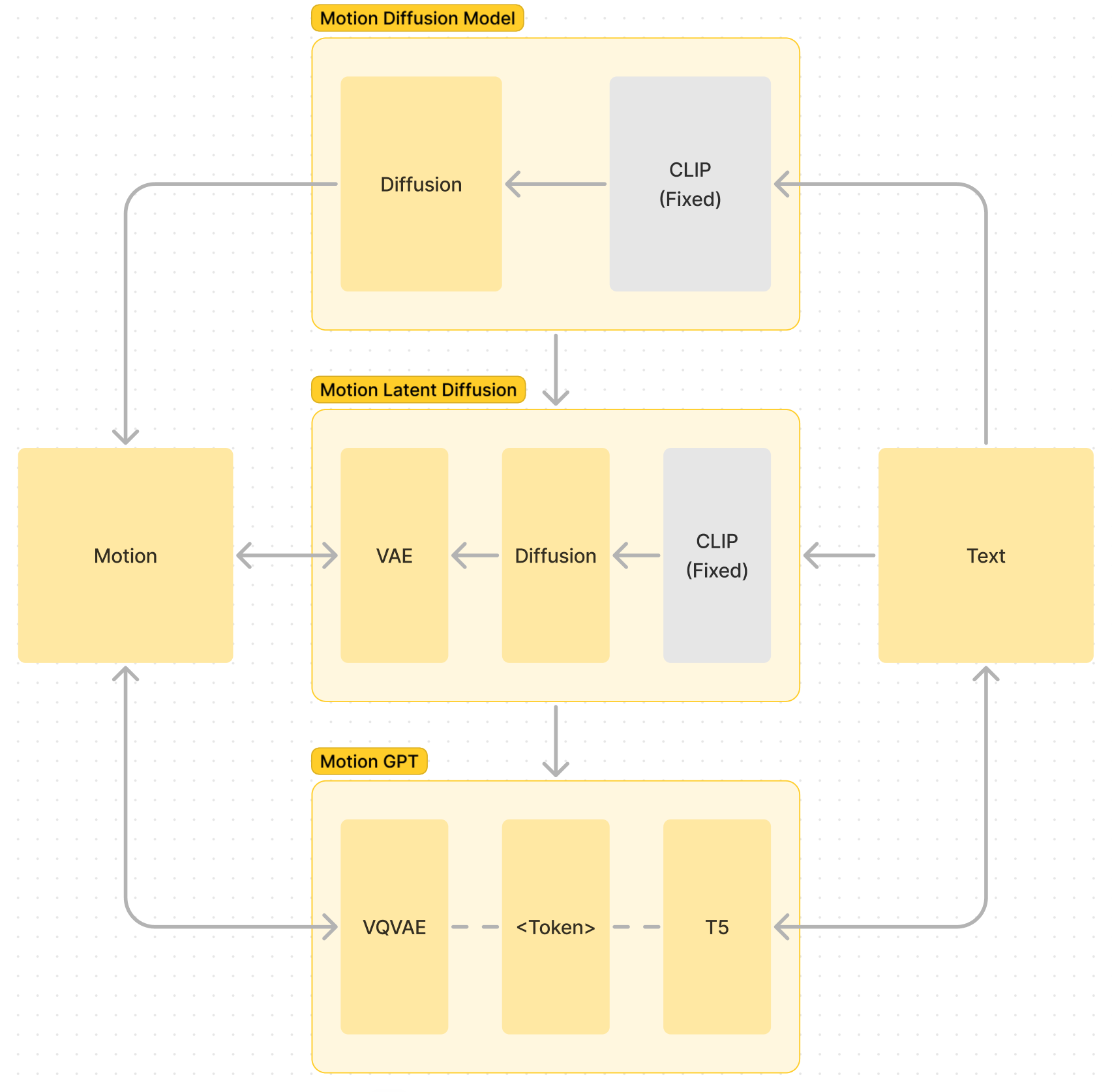
如上图所示,简单概括了在 Text2Motion 这一任务中,三个网络的架构演化:
- 在 MDM 到 MLD 的演化中,通过引入 VAE 降低生成模型理解和生成动作的门槛,从而加快生成速度
- MLD 到 MGPT 的演化中,保留了 VAE 对动作信息的蒸馏,并替换了具有更强理解的语言模型生成
当然,在这个演化过程中,也引入了一定的缺点,例如 VAE 的引入必然导致了压缩中的信息损失,基于语言模型的生成相比 Diffusion 必然降低了随机性。
而如何评估这些因素对我们训练及生成效果的影响,无疑是实验和技术选型中最重要的一环。
模型的演化与选择
扩散模型与生成多样性
对 Diffusion 的抛弃,是从早期使用扩散模型生成到现今使用语言模型中最大的转变。
扩散模型在图像生成领域取得优势,是因为它们出色的随机化多样性以及对图像高频特征的良好学习。但当这个优点转移到运动生成领域时,就不再那么突出了。
对于人类运动而言,一方面受限于肢体物理约束和动作功能性,很难有足够丰富的动作形式;另一方面,由于物理限制,运动中往往缺乏高频信息。这两个特点,使得扩散模型在运动生成领域的优势不像图像领域那么明显。
VAE 与 Token 化
VAE 最初在 MLD 中被引入作为中间层,用于解决在复杂 SMPL 序列数据上运行扩散模型的低效问题。
VAE 注意到了人类运动缺乏高频特征和运动范围受限的问题,因此引入 VAE 对生成目标进行压缩。这种压缩在 MGPT 中得到进一步发展,使用 Token 对运动进行更高层次的抽象表征。
然而,随着这一过程的推进,我们对运动的表达越发依赖于编码系统的鲁棒性,不可避免地引入了一些失真。例如在实验中,VAE 训练质量导致了或多或少的动作抖动。乃至引入 VQVAE 后,运动方向信息也出现了丢失。
CLIP 与跨模态理解
CLIP 出色的语义能力和 DALLE 的优异表现,在三年前再次点燃了 CV 在跨模态领域的热情。但在某种程度上,它也限制了相关领域的研究进展。
CLIP 通过对比学习实现了文本和视觉模态的连接,但由于其无监督特性,这种对应是相对粗糙的。以图像生成为例,生成高质量图像依赖于对图像内容的详细描述和对关键词文本的调整。它确实有控制颗粒度更高的优势,但无疑也效率较低。它的优势在于面向描述生成,而难以处理更复杂的语义需求。
因此,当出现真正优秀的语言模型后,对它们进行迭代是相对主流的思路。
T5 与语义能力的提升
T5 系列模型是一个 Encoder-Decoder 架构的语言模型,也是 MotionGPT 使用的架构。
得益于语言模型的语义理解和生成能力,T5 在 MotionGPT 中同时取代了 MLD 中的 CLIP 和扩散模型的模块。它引入了远超 CLIP 的文本理解能力,同时也放弃了扩散框架多余的随机化能力。
T5 模型的加入使得基于文本的指令式、含缺省的生成成为可能。这使我们能够纳入更多贴近实际生产需求的生成方式到视野中。
ICL 与对语言模型能力的进一步需求
语言模型的引入使 Prompt 设计更直观,这进而催生了我们进一步拓展 Prompt 以更有效提出需求的需要。围绕对更多游戏设计师习惯的调研,我们意识到诸如输入风格参考、输入生成长度、基于生成结果的微调等一系列需求。
可以预见的是,随着这些复杂需求的引入,简单的 Instruct 微调逐渐难以涵盖,我们将期望生成模型拥有更强的时空理解能力、更强的连续对话修改能力,以及更强的从上下文中学习能力。这又依赖于语言模型规模的扩大。
因此,选用更强大的语言模型来实现生成任务成为了目前值得探索的主要方向之一。无论是小规模大词库易于增量训练的 RWKV,还是具有与 Encoder-Decoder 架构相似优势的 GLM 系列,都是我们进一步尝试的首选。
MotionGPT: 基于运动和语言的统一框架
本文配套的 Demo 最终选用在 MotionGPT 框架下训练并运行,取得了相对理想的结果。我们将在这一节简要介绍MotionGPT的框架和方法。
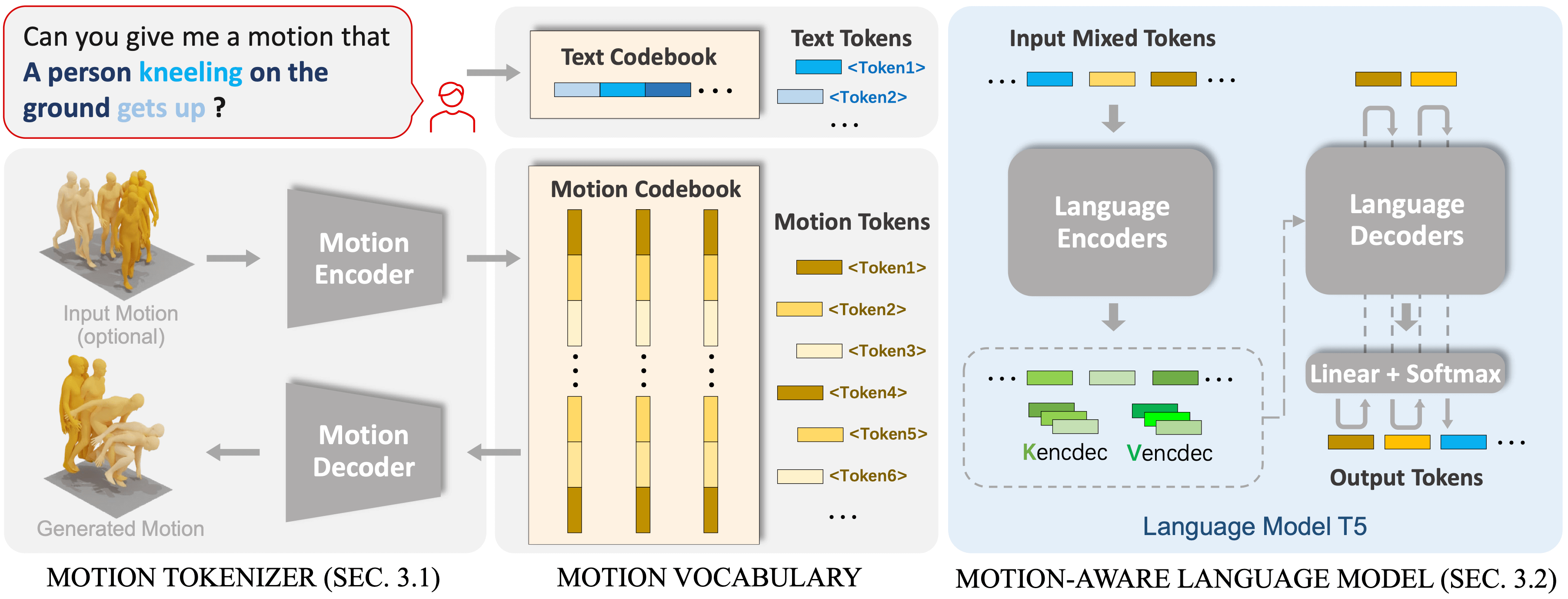
如图所示,为 MotionGPT 原文献中的插图,妥善展示了 MGPT 的框架结构。
在MotionGPT中,延续了MLD的思路,在VAE对原始运动数据压缩的基础上更进一步,将VAE的编码结果离散化压缩到码本中,使用VQVAE的方法将运动信息Token化。这一思路源自一种朴素的生活直觉——我们能通过肢体动作传达语义信息,那么肢体动作也可以被视为一种"外语",被语言模型所理解和处理。
MotionGPT通过将一系列运动数据转换为离散的运动Token,并基于这些Token进行语言模型预训练,为语言模型提供了对人体动作理解和生成的能力。
通过进一步的训练和微调,MotionGPT能够有效实现基于指令的生成,为生成提供了超越CLIP的灵活性。例如,它不仅能基于语言生成,还能根据需求填补、延续运动序列,或者根据给定运动生成相应的描述。
这一特性使得生成式AI为用户提供更自然的交互体验成为可能。
总结
对于当前动作生成领域的发展,MotionGPT 很好地在生成多样性与指令符合性之间取得了平衡。但整体学术领域对工业场景的需求理解较浅,这也为我们进一步探索数据集的设计和模型的选取提供了一定的空间。这也将导向我们接下来的一系列可能工作与展望。
实验
实验环境:Ubuntu22.04,NVIDIA GeForce RTX 4090,CUDA 11.8,12 vCPU Intel(R) Xeon(R) Platinum 8352V CPU @ 2.10GHz,Python 3.10。
实验参数:
VQVAE
batchsize:256
epoch:1500
optimizer:AdamW
learning rate: 2e-4
Pretrain
batchsize:16
epoch:200
optimizer:AdamW
learning rate: 2e-4
Finetune
batchsize:16
epoch:50
optimizer:AdamW
learning rate: 1e-4
Evaluation on CMP
| Metric | MotionGPT | MLD | MDM |
|---|---|---|---|
| Matching Score↓ | 5.426 ± 0.017 | 5.753 ± 0.019 | 5.179 ± 0.013 |
| Matching Score (Ground Truth)↓ | 5.166 ± 0.012 | 5.177 ± 0.018 | 7.220 ± 0.018 |
| R_precision (top 1)↑ | 0.044 ± 0.002 | 0.048 ± 0.002 | 0.053 ± 0.002 |
| R_precision (top 2)↑ | 0.084 ± 0.003 | 0.089 ± 0.003 | 0.097 ± 0.003 |
| R_precision (top 3)↑ | 0.122 ± 0.003 | 0.126 ± 0.003 | 0.136 ± 0.004 |
| R_precision (top 1)(Ground Truth)↑ | 0.050 ± 0.002 | 0.051 ± 0.002 | 0.030 ± 0.001 |
| R_precision (top 2)(Ground Truth)↑ | 0.094 ± 0.002 | 0.095 ± 0.003 | 0.063 ± 0.002 |
| R_precision (top 3)(Ground Truth)↑ | 0.133 ± 0.003 | 0.134 ± 0.004 | 0.096 ± 0.002 |
| FID↓ | 0.531 ± 0.018 | 1.240 ± 0.036 | 0.019 ± 0.001 |
| Diversity→ | 5.143 ± 0.052 | 5.269 ± 0.044 | 5.191 ± 0.036 |
| Diversity (Ground Truth)→ | 5.188 ± 0.070 | 5.200 ± 0.049 | 3.364 ± 0.080 |
| MultiModality ↑ | 1.793 ± 0.094 | 2.618 ± 0.115 | 2.463 ± 0.102 |
为什么 mGPT、MLD 和 MDM 在 HumanML3D 数据集上的表现差异不是很大,但在 CMP 上差距很大?
一方面,从数据集的角度来看,HumanML3D 数据集分布比较均匀,它包含大量的日常动作和体育运动动作,而且通过镜像动作实现了数据增强,有将近 29232 条数据,是我们的 3.36 倍。CMP 数据集的大部分动作数据是带有武器的格斗动作,分布比较集中。另一方面,从算法的角度来看,我们在选定模型后,对 MotionGPT 在 CMP 数据集上做了优化。
为什么不实现数据增强?
我们有考虑过通过 HumanML3D 一样的镜像方法实现数据增强。但在通过一次次改进标注、精选数据和评估生成效果后,发现数据的质量更重要。数据增强难以实现主要出于以下几点考虑:
- 一些动作的特殊性导致我们无法批量化对这个数据集进行镜像处理,比如角色死亡动作,假设描述词是”角色身体向下坠去,瘫倒在地“。如果对其镜像,”向上死亡“无论是动作还是描述,都是不合理的。
- 关于前后左右的对称方位镜像问题,我们在数据集标注优化中增加了对 root motion 的方位标注,实验结果表明这样的处理方法有利于模型学习到正确的方位信息。
- 从时间反演来看,一些动作通过倒放可能会影响模型对语义的理解,比如握住长枪冲刺,倒放的话就是拿着武器反向跑,这很奇怪。( **@ 贝伦 ** 贝佬看看反演这部分怎么说合理)
混合训练尝试
为了减少 CMP 数据集过小的问题,我们将 HumanML3D、KIT-ML 和 CMP 数据集混合起来训练模型,在评估指标上会带来巨大提升,但评估指标和视觉效果并不等价,对于部分生成结果,混合训练的模型表现不如单独使用 CMP 数据集训练的模型,这是因为不同数据集动作风格的差异改变了数据分布,进而影响了模型的性能。
此外,我们注意到一个特别大的数据集 Motion-X,起初像将其转换成 HumanML3D 的格式,用于预训练模型,或者扩充 VQ-VAE 的码本长度来增加动作的丰富性和风格化程度,但数据格式转换的工作失败了。
关于 MLM 掩码比例的尝试
MLM(Masked Language Model)在训练的过程中,会通过随机掩码(通常掩码比例设置为 15%)让模型预测被遮蔽部分的方式让模型学习。如果有大量的数据,模型有足够的例子来学习和泛化,但考虑到 CMP 数据量较小,我们尝试增加掩码比例来帮助模型更好地学习泛化。受到《Should You Mask 15% in Masked Language Modeling?》的启发,我们将 MLM 的掩码率提升到 40%,但从评估指标和视觉效果上看没有明显的变化,因此仍然采用 MotionGPT 中 15% 的设置。
Text-to-Motion 任务的拆分
原版的 MotionGPT 中包含了 Text-to-Motion、Motion-to-Text、Motion Prediction、Motion In-between 等运动相关的任务,而我们的任务只需要模型处理好 Text-to-Motion,因此在运动语言模型预训练和指令微调阶段,我们从 MotionGPT 框架中分离出 text-to-motion 任务,这使得在计算资源(一台 RTX4090)有限的情况下加速了训练过程,原来 4 天的训练耗时减少到 1 天不到,而且评估指标和视觉效果不受影响。
展望
依托于 MotionGPT 框架的强大语义理解能力和精制作的 CM 大型数据集,我们训练出了一个高质量战斗动作的文本-动作生成模型。尽管如此,随着文本生成动作技术的进一步发展,我们也认识到了在模型适应性和数据集拓展性上的一些局限。为此,我们计划持续优化算法,并探索更广泛的应用场景和更大的开源动作数据集制作。
针对工业场景的接入,我们意识到,SMPL 骨骼模型虽然为拟人动作提供了强大的支持,但其在工业习惯上的局限性也逐渐凸显。我们计划将 SMPL 模型更深入地与游戏引擎集成,以建立一个完整的用户生成流程,实现从文本到动作生成的无缝衔接。这一步将大幅度提升动作生成技术在游戏开发、影视制作等领域的实用性。
在算法优化方面,我们认识到当前使用的语言模型难以完全满足“提需求”的实际生产标准。因此,我们计划尝试引入 RWKV6 1.5B等更先进的语言模型,借助其广泛的多语言词表和相对低廉的训练成本,进一步提高生成动作的质量和多样性。同时,我们也在探索是否有更适合处理所有类人动作的通用表示,比如考虑引入 Skeleton-Aware Networks 架构,作为 VQ-VAE 使用,以期望更有效地学习和编解码骨骼动画的特征。
对于数据集质量及其生产管线的优化,我们计划让模型深入感知面向策划的语料,引入帧数微调、动画后处理(如动画的逆向动力学 IK 处理)等进一步的标度设计。对于同一动作数据,可以设计更多样化的文本标注,以提升数据集的质量和应用的广泛性。数据清洗和预处理的工作流程也将进一步优化,以确保数据的准确性和有效性,更好地满足实际生产中的需求。
最后,我们呼吁业内同仁共同参与动作数据的开源工作,以共同推动文本生成动作技术的发展,让这项技术更好地服务于更广泛的工业应用场景,推动人工智能技术在人类动作生成领域的实用化和普及化。
鸣谢
完成本篇文章的研究工作过程中,我们得到了诸多专业人士、同事、朋友和广大游戏爱好者的大力支持与帮助。在此,我们衷心感谢他们每一位的辛勤工作与宝贵贡献。
感谢Olórin、遗忘的银灵、神气的猫在数据提取方面的帮助,他们的专业能力帮助项目解决了最棘手的原始数据难题。
在数据标注这项辛苦劳动过程中做出杰出贡献的残允、Yuan、杏子、Nori、薛定谔的猫、Elm、细节、Chronos、TimEntropy、sPicaLance、甜心、水果茶、小润、柱子、水母等人,对此我们表示最诚挚的感谢。
阿Kita先生的专业知识为我们丰富标注词库提供了独到的见解与创新,我们表示由衷的感激。
对于波斯猴子先生在动画重定向上的大力技术支持和不厌其烦的反复修正调优,我们深表谢意。
感谢胡成同学在网页制作方面的精湛技艺,以及早上好先生在MaxScript脚本制作上的帮助。
最后,我们还要特别感谢Katana先生提供的专业指导意见,他的建议对我们的研究起到了关键作用。
每一位的努力与付出都是我们研究成功不可或缺的一部分。我们希望在未来继续共同推动AIGC方向科研工作的进步。再次对上述的每一位助力者表示感谢!
Comments NOTHING